IRIX Advanced Site and Server Administration Guide |
This chapter deals with the day-to-day operations of an IRIS workstation or server running the IRIX Operating System. It covers:
Starting an IRIX system. See "Starting
the System".
Shutting down an IRIX system. See "Shutting
Down the System".
Using regular expressions and metacharacters. See "Using
Regular Expressions and Metacharacters".
Using common shortcuts that are built in to the IRIX system to make
shell command system administration more convenient. See "Using
Shell Shortcuts in the IRIX System".
Creating a new shell window on a graphics workstation with customized
colors and fonts. See "Creating
a Custom Shell Window"
Performing large scale operations on many files at once. See "Finding
and Manipulating Files Automatically" and "Automating
Tasks with at(1), batch(1), and cron(1M)".
Using system utilities to automate tasks. See "Automating
Tasks with at(1), batch(1), and cron(1M)".
Checking the hardware and software configuration. See "Checking
System Configuration".
General operations, such as changing the system date or name, managing
processes and system resources, reconfiguring various system defaults.
and maintaining the File Alteration Monitor. See "General
Operations".
General procedures, including guidelines for balancing the needs of
system maintenance and the interests of your user community; suggestions
for record keeping; lists of important administrative directories and files.
See "Operating Policies".
Definition of the operating system run levels; how they are controlled
and how to change them. See "Operating
Levels".
Recovering from a system crash and analyzing what has happened. See "Maintaining a System Log Book".
To start up a system, follow these steps:
Make sure all cables (such as power, display monitor cable, and keyboard)
are properly connected. See your owner's guide and hardware guide for complete
information about cabling your particular workstation or server.
Turn on the power switches on the display monitor (or console terminal) and the computer.
The computer runs power-on diagnostics and displays some copyright messages and some system startup information. These messages appear on the console screen or on the screen of a diagnostics terminal (an ASCII terminal connected to the first serial port) of a server. A copy of these messages is also written to the /var/adm/SYSLOG file in case you miss them.
If the operating system determines that the file systems need checking, it checks them with the fsck program. fsck fixes any problems it finds before the operating system mounts the file systems. fsck will run if the system is not shut down properly, such as in the event of a power failure. For information about using fsck, see "Maintaining File Systems" in this guide, and the fsck(1M) reference page. Note that it is not necessarily a problem if fsck runs, it is merely a precaution.
The system now comes up in multiuser mode and you can log in. You should leave your system running at all times. The IRIX operating system works best when it is allowed to run continuously, so that scheduled operations and ``housekeeping'' processes can be performed on schedule.
This section describes how to turn off a workstation or server from multiuser or single-user mode.
To shut down the system from multiuser mode:
Use the who(1) command to determine which users are logged in to the operating system, if any:
who
Notify any users that the system is shutting down. Issue the /etc/wall(1M) command:
wall
Enter your message. For example, you might enter:
There is a problem with the building's power system. I will be shutting down the system in 10 minutes. Please clean up and log off. Sorry for the inconvenience, norton
When you finish entering your message, type <Ctrl-D>. The message is sent to all users on the system. They see something like this:
Broadcast Message from root Tue Oct 17 17:02:27... There is a problem with the building's power system. I will be shutting down the system in 10 minutes. Please clean up and log off. Sorry for the inconvenience, norton
Issue the /etc/shutdown command:
/etc/shutdown -y -i0 -g600
The above command specifies a 10 minute (600 second) grace period to allow users to clean up and log off. The other flags indicate that the system is to be completely shut down ( -i0) and that the system can assume that all answers to any prompts regarding the shutdown are ``yes.'' You see the following message:
Shutdown started. Fri Aug 28 17:10:57... Broadcast Message from root (console) Fri Aug 28 17:10:59 The system will be shut down in 600 seconds. Please log off now.
After ten minutes, you see this message:
INIT: New run level: 0 The system is coming down. Please wait.
The Command Monitor prompt or System Maintenance menu appears. Wait
for a Command Monitor prompt or System Maintenance menu to appear before
turning off power to the workstation or you may damage your hard disk.
You can now turn off the power.
For more information on shutting down the system, see the halt(1M) and shutdown(1M) reference pages. Remember that you should shut down the system only when something is wrong or if modifications to the software or hardware are necessary. IRIX is designed to run continuously, even when no users are logged in and the system is not in use.
If the system is in single-user mode, follow these steps:
Use the shutdown command to turn off the system and guarantee file system integrity. As root, enter the command:
shutdown -y -i0 -g0
where:
-y assumes yes answers to all questions, -i0 goes to state 0 (System Maintenance Menu), and -g0 allows a grace period of 0 seconds.
You see a display similar to this one:
Shutdown started. Fri Aug 28 17:11:50 EDT 1987 INIT: New run level: 0 The system is coming down. Please wait.
The system stops all services and the Command Monitor prompt or System Maintenance Menu appears.
Wait for the Command Monitor prompt or System Maintenance menu to appear
or for a message that the system can be powered off before turning off
power to the computer. Doing so prematurely may damage your hard disk.
Turn off power to the computer.
There are shortcuts available to you when you wish to define large numbers of files or directories in your IRIX shell commands. These shortcuts are known as "regular expressions." Regular expressions are made up of a combination of alpha-numeric characters and a series of punctuation characters that have special meaning to the IRIX shells. These punctuation characters are called metacharacters when they are used for their special meanings with shell commands. The following is a list of the IRIX metacharacters:
| Metacharacter | Meaning |
|---|---|
| * | wildcard |
| ? | single character wildcard |
| [] | set definition marks |
The asterisk (*) metacharacter is a universal wildcard. This means that the shell interprets the character to mean any and all files. For example, the command:
cat *
tells the shell to concatenate all the files in a directory, in alphabetical order by filename. The command:
rm *
tells the shell to remove everything in the directory. Only files will be removed, though, since a different command, rmdir(1) is used to remove directories. However, the asterisk character does not always have to refer to whole files. It can be used to denote parts of files as well. For example, the command:
rm *.old
will remove all files with the suffix.old on their names.
The single character wildcard is a question mark (?). This metacharacter is used to denote a wildcard character in one position. For example, if your directory contains the following files:
file1 file2 file3 file.different
and you wish to remove file1, file2, and file3, but not file.different, you would use the command:
rm file?
If you used an asterisk in place of the question mark, all your files would be removed, but since the question mark is a wildcard for a single space, your desired file is not chosen.
Square brackets denote members of a set. For example, consider the list of files used in the example of the single character wildcard. If you wanted to remove file1 and file2, but not file3 or file.different, you would use the following command:
rm file[12]
This command tells the shell to remove any files with names starting with file and with the character 1 or 2 following, and no other characters in the name. Each character in the brackets is taken separately. Thus, if our example directory had included a file named file12, it would not have been removed by the above command. You can also use a dash (-) to indicate a span of characters. For example, to remove file1, file2, and file3, use the following command:
rm file[1-3]
Alphabet characters can be spanned as well, in alphabetical order. The shell does pay attention to upper case and lower case letter, though, so to select all alphabet characters within square brackets, use the following syntax:
[a-z,A-Z]
You can use the square brackets in combination with other metacharacters as well. For example, the command:
rm *[2,3]
removes any files with names ending with a 2 or 3, but not file1 or file.different.
IRIX provides a number of facilities that can be used for your convenience as you administer and use the system. Some of these shortcuts are available through the command shells (/usr/bin/csh, /usr/bin/tcsh, /usr/bin/sh and /usr/bin/ksh) and others are made available through the computer hardware itself. These shortcuts are useful because they minimize keystrokes. While minimizing keystrokes may seem to be a minor concern at first glance, an administrator who issues lengthy and complex command lines repeatedly may find these shortcuts a handy and necessary time-saving feature.
The IRIX C Shell (/bin/csh) provides several features that can be used to minimize keystrokes for routine tasks. Complete information about these and many other features of the C Shell is available in the csh(1) reference page. Among the features provided are:
The /usr/bin/tcsh program is an improved version of the C shell. In addition to the C shell features listed above, this shell offers many new features. A few of the most useful to system administrators are:
Better command line editing using emacs and vi key commands.
Improved history mechanisms, including time stamps for each command.
Built-in mechanisms for listing directory contents and for executing commands at specific times or intervals.
There are many more features implemented in Tcsh, and all of them are covered in the tcsh(1) reference page.
The Bourne shell (/bin/sh) provides fewer features than the C shell, but in its place offers a level of access to the shell that contains far fewer restrictions and intervening layers of interface. For example, you can write shell script programs directly from the shell prompt with Bourne shell. Input and output redirection and command aliasing are supported with the Bourne shell, but no command history, job control, or filename completions are available. For a complete discussion of the Bourne shell and its features, see the sh(1) reference page.
The Korn shell was developed to provide the best features of both the C shell and the Bourne shell. The /bin/ksh program provides the ease of shell programming found in the Bourne shell, along with the job control, history mechanism, filename completion, and other features found in the C shell. This shell has changed many of the ways these features are implemented, and also provides improved command line editing facilities. See the ksh(1) reference page for complete information on this shell. Useful features include:
The system hardware for graphical workstations (and some X-terminals) can provide you with shortcuts. These may not be available to server administrators who rely solely on character-based terminals for their administration. Using the graphics console of your system, you can cut and paste between windows without using pull-down or pop-up menus of any sort. Using the pop-up menu, you can manipulate your windows completely.
Note that you can customize the action of your mouse buttons. All examples in this section assume the default mouse button meanings are being used. If you have modified your mouse action, you must allow for that modification before you use these techniques.
For complete information on using the pop-up windows, see your IRIS Essentials book, either in hard copy or on screen through the IRIS InSight software package.
The most common mouse shortcut is to cut, copy, and paste between windows on your screen. Here is how you do it:
Find the cursor controlled by your mouse on your screen. It should appear
as a small arrow when it is positioned in the working area of one of your
windows, or as an "X" when it is positioned on your background
screen, or as some other figure when it is positioned on the frame of a
window or in the working area of an application's window. If you can't
locate the cursor immediately, move the mouse around a bit and look for
motion on your screen. You should find the cursor easily.
Place the cursor at the beginning of the text you wish to paste between
windows and press the leftmost key on the top of the mouse. Now, keeping
the mouse button depressed, move the cursor to the end of the text you
wish to paste. The intervening area of the window changes color to show
the selected text. If you are selecting a large section of text, it is
not necessary to move the cursor over every space. You may move the cursor
directly to the end point and all intervening text will be selected. It
is not possible to select "columns" of text or several disconnected
pieces of text at once. When you have moved the cursor to the desired end
point, release the mouse button. The text remains highlighted.
Now move the cursor to the window you want to paste the text into and
make certain the window is ready to receive the pasted text. For example,
if you are pasting a long command line, make certain that there is a shell
prompt waiting with no other command already typed in. If the pasted matter
is text into a file, make certain that the receiving file has been opened
with an editor and that the editor is in a mode where text can be inserted.
To paste the text, place the cursor in the receiving window and press
the middle mouse button once quickly. Each time you press the middle button,
the selected text will be pasted into the receiving window. Sometimes it
takes a moment for the text to appear, so be patient. If you press the
button several times before the text appears, you will paste several copies
of your text.
You can also paste your selected text to the bottom of a window (including the window from which you selected the text). Press the rightmost mouse button while the cursor is in that window and select the send option from the pop-up menu that appears.
The text you originally selected remains selected until you select new text somewhere else or until you place the cursor back in the original window and click once on the leftmost mouse button.
If you need a new shell window, you can use the mouse to create one. Follow these steps:
With the cursor in a shell window, press the rightmost button on your mouse. A pop-up menu appears:
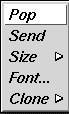
Figure 2-1 : Shell Pop-Up Menu
The last item on the pop-up menu is the clone option. There is a small triangle to the right of this option. This triangle indicates that there are more sub-choices available in another pop-up menu. While keeping the button on the mouse depressed, move the mouse down until the clone option is highlighted and the sub-menu pops up, showing various shell window cloning options. These options create another shell window functionally identical to the one in use. This is why the option is called cloning. The text and background colors of the current window are carried forward to the cloned window, and the selections in the sub-menu specify the number of lines in the new window. You can choose to have the same number of lines in the cloned window as in the current window, or to have 24, 40, or 60 lines.
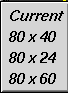
Figure 2-2 : Shell Window Cloning Submenu
Select the size you want by moving the mouse down to highlight each option and releasing the mouse button when the option you desire is highlighted. The new window will appear on your screen presently. You may repeat this process as often as you like on any shell window.
IRIX allows you to create a shell window using any colors you like from the palette on your graphics workstation. You may also select any font you prefer from the font set on your system. The xwsh(1) command creates the shell window, and the options to this command control the various fonts, colors, and other features available to you.
For a complete list of the features available with xwsh(1), see the xwsh reference page. The most commonly used features are described here in the following examples.
To create a simple shell window with a dark gray background and yellow text, issue the following command:
xwsh -fg yellow -bg gray40 &
The above command generates a new window and a new shell using the colors specified. The window will use the default font selection and window size, since these attributes were not specified. The command that created the shell was placed in the background, so the shell does not tie up the window where you gave the command. You can always place a command in the background by adding the ampersand character (&) to the end of the command line. For more information on placing processes in the background, see the csh(1) reference page.
There are 100 shades of gray available. Gray0 is the darkest, and is virtually black. Gray100 is the lightest and is virtually white. The effect of selecting foreground (text) in yellow and background in gray40 is similar to yellow chalk on a gray chalkboard. For a complete list of the available colors in your palette, use the colorview(1) command. This brings up a window with the list of colors in a scrollable list, and a display window to show a patch of the currently selected color.
In the next example, we change the colors to black on a sky blue background (high contrast between the foreground and background makes reading the screen easier), and we add a specification for the size of the window.
xwsh -fg black -bg skyblue -geometry 80x40 &
The first number in the geometry option is 80, indicating that the new shell window should be 80 characters wide (this is the default). The second number indicates the desired number of lines on the screen, in this case 40. Once again, the xwsh command has been placed in the background by adding the ampersand character to the end of the command line.
You can make your new shell come up on your desktop as an icon by adding the -iconic flag to any xwsh command.
To select a font other than the default, you can use the on-screen font selection utility, or you can specify the font on the command line. It is a great deal easier to use the on-screen font selection utility, as you must specify a great number of attributes for the font on the command line. Also, it frequently takes a great number of selections before you settle on a font, a weight (regular or bold, condensed or normal) and a font size that appeals to you. Using the on-screen font utility, you can preview what each selection will look like on your windows.
Once you have made your selections, you can copy and paste the font selection information and the rest of your xwsh command into a shell script file for convenient future use. For example, here is an xwsh command line that specifies the IRIS-specific font haebfix in a medium weight with normal spacing, 15 pixels tall. The remaining information is generated by the font selection utility for the shell.
xwsh -iconic -fg yellow -bg grey40 -geometry 80x40 -fn \ -sgi-haebfix-medium-r-normal--15-150-72-72-m-90-iso8859-1 &
Note that in your shell script, the above command appears all on one line. Due to formatting constraints, the command is broken across two lines in this example.
For complete information on using the font selection utility in xwsh and the xfontsel(1) command, see Chapter 2 of the IRIS Utilities Guide.
The IRIX system provides several tools for manipulating large numbers of files quickly. Some of the most common are described below:
The find(1) utility locates files and can invoke other commands
to manipulate them.
The sed(1) program edits files using pre-determined commands.
Many other programs have recursive options, with which you can quickly operate on files that are in many levels of subdirectories.
The find(1) command is used to find files and possibly execute commands on the files found. It starts at a given directory and searches all directories below the starting directory for the specified files. A basic find command line looks like this:
find . -name <filename> -print
This command searches from the current directory until it finds the exact <filename> and then displays its location on your screen. You can also use regular expressions (see "Using Regular Expressions and Metacharacters") in your searches.
The following command line searches for files that have been changed after the time /tmp/file was last modified. If you use touch(1) to create /tmp/file with an old date, this command can help you find all files changed after that date.
find / -local -newer /tmp/file -print
You can use find to locate files and then to run another command on the found files. This example shows how to locate a file in a user's directory:
cd /usr/people/trixie find . -name 'missingfile' -print
In this example, the period (.) indicates the current directory, the -name option indicates that the next argument in quotes is the name of the file you are looking for, and the -print option tells find to display the pathname of the file when the file is located.
The next example shows how to change the permissions on all the files in the current directory and in all subdirectories:
find . -name '*' -local -exec chmod 644 {} \;
The option immediately following the find command is a period (.). This indicates to find that the search is to begin in the current directory and include all directories below the current one. The next flag, -name, indicates the name of the files that are being found. In this case, all files in the directory structure are selected through the use of the asterisk metacharacter (*). See "Using Regular Expressions and Metacharacters" for more information on metacharacters and regular expressions.
The -local option indicates to find that the search is limited to files that physically reside in the directory structure. This eliminates files and directories that are mounted via the Network File System (NFS). The -exec option causes find to execute the next argument as a command, in this case chmod 644. The braces, { }, refer to the current file that find is examining.
The last two characters in the command line are part of the chmod command that will be executed (with the -exec option) on all files that match the search parameters. The backslash (\) is necessary to keep the shell from interpreting the semicolon (;). The semicolon must be passed along to the chmod process. The semicolon indicates a carriage return in the chmod command.
find has several other useful options:
The find and cpio commands can be used to easily and safely copy a directory or a directory hierarchy as long as the user has permissions to access the directory. To copy a directory with all its files, or an entire hierarchy of directories and their files, use commands like the following:
mkdir new_directory_name cd the_directory_you_want_to_copy find . -print | cpio -pdlmv new_directory_name
This command sequence preserves the symbolic links in the new directory as well as transparently cross file system boundaries.
You can use sed(1), the Stream Editor, to automate file editing. sed follows an editing script that defines changes to be made to text in a file. sed takes a file (or files), performs the changes as defined in the editing script, and sends the modified file to the standard output. sed is fully described in the IRIX Development Option documentation and in the sed(1) reference page, which is included in your IRIX distribution. The IRIX Development Option is available for separate purchase from Silicon Graphics.
Recursive commands can save you a lot of time. For example, to change the ownership of all the files and directories in a directory recursively, and all of the files and directories in all of the subdirectories below that, you can use the recursive option with chown(1):
chown -R username directory
Some of the other commands in the IRIX system that have recursive options are:
ls -R rm -r chgrp -R
If you want to use a particular command recursively, but it does not have a recursive option, you can run the command using find. See "Using find to Locate Files".
Note that using recursive options to commands can be very dangerous in that the command automatically makes changes to your files and file system without prompting you in each case. The chgrp command can also recursively operate up the file system tree as well as down. Unless you are sure that each and every case where the recursive command will perform an action is desired, it is better to perform the actions individually. Similarly, it is good practice to avoid the use of metacharacters (described in "Using Regular Expressions and Metacharacters") in combination with recursive commands.
You can use the at(1), batch(1), and cron(1M) utilities to automate many of your usual tasks, both as an administrator and as a user. These utilities perform similar functions. All execute commands at a later point in time. The difference between the commands is that at executes the given command at one specific time; cron sets up a schedule and executes the command or commands as often as directed, according to the schedule; and batch executes the commands when system load levels permit the execution.
If you have a task to process once at a later point in time, use at. For example, if you wish to close down permissions on a public directory at midnight of the current day, but you do not need to be present when this occurs, you could use the command string:
at 2400 July 14 chmod 000 /usr/public <Ctrl-D>
It is required that the at command itself and the date and time of the command be placed alone on a line. When you press <Return>, you do not see a prompt; at is waiting for input. Enter the command to be executed just as you would type it at a shell prompt. After entering the command, press <Return> again and enter <Ctrl-D> to tell at that no more commands are forthcoming. You can use a single at command to execute several commands at the appointed time. For example, if you want to close the public directory and change the message of the day to reflect this closure, you can create the new message of the day in the file /tmp/newmesg, and then issue the following command string:
at 2400 July 14 chmod 000 /usr/public mv /etc/motd /etc/oldmotd mv /tmp/newmesg /etc/motd <Ctrl-D>
By default, any output of commands executed using at is mailed to the executing user through the system electronic mail. You can specify a different location for the disposition of output by using the standard output redirects, such as pipes (|) and file redirects (>). See your command shell documentation for a complete description of redirecting the standard output.
For complete information on the at command, see the at(1) reference page.
The batch command works just like the at command, except that you do not specify a time for the command or commands to be executed. The system determines when the overall load is low enough to execute the commands, and then does so. As with all other cron subsystem commands, the output of the commands is mailed to you unless you specify otherwise. batch is useful for large CPU-intensive jobs that slow down the system or cripple it during peak periods. If the job can wait until a non-peak time, you can place it on the batch queue until the system executes it. For complete information on the batch command, see the batch(1) reference page.
If you desire to have a command executed regularly on schedule, the cron command and subsystem provide a precise mechanism for scheduled jobs. The at and batch commands are technically part of the cron subsystem and use cron to accomplish their tasks. The cron command itself, though, is the most configurable command of the subsystem.
You use cron by setting up a crontab file, where you list the commands you would like to have executed and the schedule for their execution. Complete information on setting up your crontab file is available in the cron(1M) and crontab(1) reference pages.
cron is useful for scheduling network backups, checking the integrity of the password file, and any other scheduled tasks that do not require interaction between you and the system. By default, cron mails the results or output of the command to the user who submitted the crontabs file, so if you use cron to schedule something like a pwck(1M), the results of the test are mailed to you and you can interpret them at your convenience.
Note that you must restart cron after each change to a crontabs file, whether made through the cron utility or the at command, for the changes to take effect.
IRIX provides two commands that allow you to check your system hardware and software configurations. The hinv(1M) and versions(1M) commands display the hardware and software inventories, respectively.
The hinv command displays the machine's hardware inventory. hinv can be run from the Command Monitor or from your system shell prompt. Pertinent information such as the processor type, amount of main memory, and all disks, tape drives, or other devices is included. A sample hinv output for a typical workstation is:
1 100 MHZ IP22 Processor FPU: MIPS R4010 Floating Point Chip Revision: 0.0 CPU: MIPS R4000 Processor Chip Revision: 3.0 On-board serial ports: 2 On-board bi-directional parallel port Data cache size: 8 Kbytes Instruction cache size: 8 Kbytes Secondary unified instruction/data cache size: 1 Mbyte Main memory size: 64 Mbytes Vino video: unit 1, revision 1 Iris Audio Processor: version A2 revision 4.1.0 Integral Ethernet: ec0, version 1 CDROM: unit 4 on SCSI controller 0 Disk drive: unit 1 on SCSI controller 0 Integral SCSI controller 0: Version WD33C93B, revision D Graphics board: Indy 24-bit
If a piece of peripheral hardware installed on your system does not appear in the hinv output, it may or may not be an indication of trouble with your hardware. Some peripherals connected to the system by a board on a VME bus will not be identified when running hinv from the Command Monitor. First, you should invoke hinv from a system shell prompt; If your peripheral is still not recognized, attempt to reseat the board in its socket and check that it is using the correct SCSI address. If this does not relieve the problem, the hardware itself may be defective. Note also that most devices are not recognized by hinv until the MAKEDEV(1M) command has been run after their installation.
The versions command gives you an inventory of software packages that have been installed using inst(1M). This command can only be run at the system shell prompt, not from the Command Monitor. Software installed by other means is not included in the versions output. Along with the names of the software products, the release revision level numbers are displayed. By default, the output of versions includes all the products and their subsystems and is typically several hundred lines long, so it is often convenient to redirect the output to a file that you can view at your convenience. For a more general look at the products you have installed, without the list of specific subsystems, use the -b (brief) flag.
A sample versions -b output reads as follows (an actual listing will be much longer):
I = Installed, R = Removed Name Date Description I 4Dwm 04/29/93 4Dwm -- Default Window Manager, 5.3 I demos 04/29/93 Graphics Demonstration Program, 5.3 I desktop_eoe 04/29/93 Desktop Environment, 5.3 I dps_eoe 04/29/93 Display PostScript, 2.0 I eoe1 04/29/93 Execution Only Environment 1, 5.3 I eoe2 04/29/93 Execution Only Environment 2, 5.3 I insight 04/29/93 IRIS InSight Viewer, 2.1 I motif_eoe 04/29/93 Motif Execution Only Environment I nfs 04/29/93 Network File System, 5.2
The gfxinfo command is useful for determining the graphics hardware installed in the system. It is in the /usr/gfx directory, which is not on any of the standard search paths. Thus gfxinfo typically needs full path name for execution. It requires no arguments to run.
An sample output for an Indy:
% /usr/gfx/gfxinfo
Graphics board 0 is "NG1" graphics.
Managed (":0.0") 1280x1024
24 bitplanes, NG1 revision 3, REX3 revision B,
VC2 revision A
MC revision C, xmap9 revision A, cmap revision C,
bt445 revision A
Display 1280x1024 @ 60Hz, monitor id 12
This command provides much more information about the graphics system than the hinv command (hinv would simply return Indy 24-bit). From the output of gfxinfo you can determine the number of screens and their pixel resolutions, bitplane configurations, component revision levels, and monitor types. There is no reference page for gfxinfo.
uname returns information such as the OS version and hostname. The -a options gives a complete list of the uname output. See the reference page for a description of all the uname options and fields.
lpstat with the -a option will show all the printers configured for the lp spooling system and also give their status. For more information on the lpstat command, see "lpstat: Report lp Status" or the lpstat reference page.
This section covers general system operations. Topics are:
"Checking
the System Configuration".
"Altering
the System Configuration".
"Changing
the Name of a System".
Information on specific parts of the system is presented in other chapters. For example, information on system security is covered in Chapter 12, "System Security."
Also, defaults for tape and other backup operations (such as the default tape drive) are covered in Chapter 6, "Backing Up and Restoring Files." Defaults for shell types and user groups are covered in Chapter 3, "User Services."
You can quickly check the configuration of a workstation or server with the chkconfig(1) command. The /sbin/chkconfig utility reports the state of various process daemons (that is, whether or not they are supposed to be active).
For example, enter the chkconfig command:
chkconfig
You see a display similar to this:
Flag State ==== ===== acct off audit off automount on fmlicserv off gated off lockd on mrouted off named off network on nfs on noiconlogin off nsr on quotacheck off quotas off routed on rtnetd off rwhod off sar on snmpd on timed on timeslave off verbose off visuallogin on windowsystem off yp on ypmaster off ypserv off
This example is typical for a networked workstation with the Network File System (NFS) option installed. The left column of the output describes a system feature, and the right column indicates whether it is on or off. The following list provides more specific information about each system feature:
Note that if a daemon is enabled using chkconfig, it does not necessarily mean that the daemon starts up immediately, or that it is running successfully. To verify that a daemon is running, use the ps(1) command to identify what processes are running on the system. For example, the command:
ps -ef
produces output similar to this:
| UID | PID | PPID | C | STIME | TTY | TIME | COMMAND |
|---|---|---|---|---|---|---|---|
| root | 0 | 0 | 0 | Aug 3 | ? | 0:00 | sched |
| root | 1 | 0 | 0 | Aug 3 | ? | 0:45 | /etc/init |
| root | 2 | 0 | 0 | Aug 3 | ? | 0:08 | vhand |
| root | 3 | 0 | 0 | Aug 3 | ? | 0:09 | bdflush |
This example is edited for simplicity. An actual, full ps listing shows many more active processes.
To view information about specific processes, and avoid searching through a large ps listing, you can filter the listing with the grep(1) or egrep(1) commands. For example, to look at process information for only the NFS daemons, use this command:
ps -ef | egrep 'nfsd|biod'
The output of this command is similar to this (assuming you have NFS installed and running):
root 120 1 0 09:40:05 ? 0:02 /usr/etc/nfsd 4 root 122 12 0 0 09:40:05 ? 0:02 /usr/etc/nfsd 4 root 123 12 0 0 09:40:05 ? 0:02 /usr/etc/nfsd 4 root 124 12 0 0 09:40:05 ? 0:02 /usr/etc/nfsd 4 root 126 1 0 09:40:05 ? 0:00 /usr/etc/biod 4 root 127 1 0 09:40:05 ? 0:00 /usr/etc/biod 4 root 128 1 0 09:40:05 ? 0:00 /usr/etc/biod 4 root 129 1 0 09:40:05 ? 0:00 /usr/etc/biod 4 root 131 1 0 09:40:11 ? 0:00 /etc/mount -at nfs ralph 589 55 0 11 15:25:30 ttyq1 0:00 egrep nfsd|biod
Note that the final entry in the ps listing is the process that produced the listing and that it is the only non-root process to have nfsd or biod in its name.
You can use the chkconfig command to change some aspects of system configuration. To determine which aspects of a system you can alter with
chkconfig, enter the chkconfig command:
chkconfig
You see a list of configuration options, which are described in "Checking the System Configuration" If you use the -s option, you see a list that is sorted by whether the configuration item is on or off.
To change a configuration option, use the chkconfig command with two arguments: the name of the option you wish to change and the new status of the configuration (on or off). You must have root privilege to change a system configuration.
For example, to turn on detailed process accounting, log in either as root or as the system administrator, and enter:
chkconfig acct on
To turn off process accounting, enter:
chkconfig acct off
Some aspects of system configuration do not take effect until the system is shut down and rebooted because startup scripts, which are in the directory /etc/init.d, are run when the system is booted up and brought to multiuser mode. These scripts read the files that chkconfig sets to determine which daemons to start.
Some configuration items that can be controlled by chkconfig may not be displayed by chkconfig. These include:
If you want to see these flags in the chkconfig menu, you can use the -f option to force chkconfig to create a configuration file for the options:
chkconfig -f nocleantmp on
In this example, chkconfig creates a configuration file called nocleantmp in the directory /etc/config.
At least once a week, you should run the pwck(1M) and grpck(1M) programs to check your /etc/passwd and /etc/group files for errors. You can automate this process using the cron(1) command, and you can direct cron to mail the results of the checks to your user account. For more information on using cron to automate your routine tasks, see "Automating Tasks with at(1), batch(1), and cron(1M)".
The pwck and grpck commands read the password and group files and report any incorrect or inconsistent entries. Any inconsistency with normal IRIX operation is reported. For example, if you have /etc/passwd entries for two user names with the same User Identification (UID) number, pwck will report this as an error. grpck performs a similar function on the /etc/group file. Note that the standard passwd file shipped with the system generates several errors.
These system-wide defaults affect programs and system functions:
the system display
the time zone
the name of the system
the network address
the default system printer
Some of these defaults are described more thoroughly in specific sections of this guide, but they are all presented here to provide a more thorough overview of the IRIX system.
You can make the output of programs and utilities running on one system appear on the screen of another system on the same network by changing the DISPLAY environment variable. This is useful if your network includes graphical systems and non-graphical servers. In order to view information from the server graphically, you reset the display to a graphics workstation.
For example, if your server has only a character-based terminal as its console and you wish to run gr_osview(1M) to visually inspect your CPU usage, you would issue commands similar to these on the server:
setenv DISPLAY graphics_machine:0 gr_osview
When you invoke gr_osview, the window with the output will appear on the machine name you specify. In this example, graphics_machine was used in place of the system name. The :0 used after the machine name indicates that display monitor 0 (the graphics console) should be used to display the output. When you have finished using the graphics console, be sure to reset the display by issuing this command on the server:
setenv DISPLAY local_server:0
where local_server is the name of your server.
To set the time zone of the system, edit the file /etc/TIMEZONE. For a site on the east coast of the United States, the file might look something like this:
# Time Zone TZ=EST5EDT
The line TZ=EST5EDT means:
The current time zone is Eastern Standard Time.
It is 5 hours to the east of Greenwich mean time.
Daylight saving time applies here (EDT).
The TZ environment variable is read by init(1) when the system boots, and the value of TZ is passed to all subsequent processes. For complete information about setting your time zone, see the timezone(4) reference page.
If you have a multi-processor system, the mpadmin(1M) and pset(1M) commands allow you to change the way programs are assigned to the various processors on your system. To determine if your system is multi-processor, use the hinv(1M) command. A multi-processor system returns information similar to the following in its hinv output:
Processor 0: 40 MHZ IP7 Processor 1: 36 MHZ IP7 Processor 2: 40 MHZ IP7 Processor 3: 40 MHZ IP7 Processor 4: 40 MHZ IP7 Processor 5: 40 MHZ IP7 Processor 6: 40 MHZ IP7 Processor 7: 40 MHZ IP7
Or, alternately, output similar to the following:
8 40 MHZ IP7 Processors
A single-processor system returns information similar to the following for the hinv command:
1 100 MHZ IP22 Processor
If you have only one processor on your system (and the vast majority of systems have only one processor) these commands still operate, though they have no useful purpose.
The mpadmin command allows you to ''turn off'' processors, report various states of the processors, and move system functions such as the system clock to specific processors. The pset command is used both to display and modify information concerning the use of processor sets and programs running in the current system. The pset command provides a much more detailed level of control of processes and processors.
For complete information on mpadmin(1M) and pset(1M), see the respective reference pages.
The name of the system is stored in several places. If you wish to change the name of your system, you must change all these files together or your system will not function correctly:
in the file /etc/sys_id
in the file /etc/hosts (for networking purposes)
in a kernel data structure, which you read and set with either hostname(1)
or uname(1)
in an NIS map on the NIS master server, if you are running NIS
Note that you should not arbitrarily change the name of a running workstation. Many programs that are started at boot time depend on the name of the workstation.
To display the name of the system, use the hostname command with no arguments:
hostname
This displays the name of the system. The uname command also displays the name of the system, along with other information.
To change the name of the workstation, follow these steps:
Log in as root.
Edit the file /etc/sys_id. Change the name of the host to newname.
Write and exit the editor.
You must also change the name of the host in any network files, such
as /etc/hosts, and possibly in the NIS map on the master NIS server.
Reboot your system.
The name of the workstation is now changed. When the workstation is booted, all programs that are started at boot time, and read the host name when they start, now use the correct host name.
For information about the Internet address of a workstation, see Chapter 15, "Understanding Silicon Graphics' Networking Products." For more information about the name of the system, see the hostname(1) and uname(1) reference pages.
The system's network address (IP address) is covered more thoroughly in Chapter 15, "Understanding Silicon Graphics' Networking Products."
To set the network address, follow these steps:
Place the network address in /etc/hosts on the same line as the
system name.
If you use the network information service (NIS), place the name of
your domain in the file /var/yp/ypdomain, if it is installed.
Use the nvram(1M) command to set the variable netaddr to the IP number of the machine. For example:
nvram netaddr 192.13.52.4
The lpadmin(1M) command sets the default printer. This command sets the default printer to laser:
lpadmin -dlaser
Note that the printer laser must already exist and be configured. For complete information on setting up printers, see Chapter 9, "Administering Printers."
Just as files can use up your available disk space, too many processes going at once can use up your available CPU time. When this happens, your system response time gets slower and slower until finally the system cannot execute any processes effectively. If you have not tuned your kernel to allow for more processes, the system will refuse new processes long before it reaches a saturation point. However, due to normal variations in system usage, you may experience fluctuations in your system performance without reaching the maximum number of processes allowed by your system.
Not all processes require the same amount of system resources. Some processes, such as database applications working with large files, tend to be disk intensive, requiring a great deal of reading from and writing to the disk as well as a large amount of space on the disk. These activities take up CPU time. Time is also spent waiting for the hardware to perform the requested operations. Other jobs, such as compiling programs or processing large amounts of data, are CPU intensive, since they require a great number of CPU instructions to be performed. Some jobs are memory intensive, such as a process that reads a great deal of data and manipulates it in memory. Since the disk, CPU, and memory resources are limited, if you have more than a few intensive processes running at once on your system, you may see a performance degradation.
As the administrator, you should be on the lookout for general trends in system usage, so you can respond to them and keep the systems running as efficiently as possible. If a system shows signs of being overloaded, and yet the total number of processes is low, your system may still be at or above reasonable capacity. The following sections show four ways to monitor your system processes.
top and gr_top are the most convenient utilities provided with IRIX to monitor the top CPU-using processes on your system. These utilities display the top such processes dynamically, that is, if a listed process exits, it is removed from the table and the next-highest CPU-using process takes its place. gr_top graphically displays the same information as top. If you are using a non-graphics server, you cannot use gr_top locally, but you can use it if you set the display to another system on the network that does have graphics capability. For complete information on configuring and using top and gr_top, consult the top(1) and gr_top(1) reference pages. For information on resetting the display, see "Setting the System Display".
osview and gr_osview are utilities that display kernel execution statistics dynamically. If you have a graphics workstation, you can use the gr_osview(1) tool, which provides a real-time graphical display of system memory and CPU usage. osview provides the same information in ASCII format. You can configure gr_osview to display several different types of information about your system's current status. In its default configuration, gr_osview provides information on the amount of CPU time spent on user process execution, system overhead tasks, interrupts, and idle time. For complete information on osview and gr_osview, see the osview(1) and gr_osview(1) reference pages.
The System Activity Reporter, sar, provides essentially the same information as osview, but it represents a ``snapshot'' of the system status, not a dynamic reflection. Because sar generates a single snapshot, it is easily saved and can be compared with a similar snapshot taken at another time. You can use sar automatically with cron to get a series of system snapshots over time to help you locate chronic system bottlenecks. For complete information on sar, see the sar(1) reference page.
The ps - ef command allows you to look at all the processes currently running on your system. ps - ef output looks very similar to Table 2-3:
| Name | PID | PPID | C | Time | TTY | CPU Time | Process |
|---|---|---|---|---|---|---|---|
| joe | 23328 | 316 | 1 | May 5 | ttyq1 | 1:01 | csh |
In this table, the process shown is for the user ``joe.'' In a real situation, each user with processes running on the system is represented. Each field in the output contains some useful information.
For even more information, including the general system priority of each process, use the -l flag to ps. For complete information on interpreting ps output, see the ps(1) reference page.
IRIX provides methods for users to force their CPU-intensive processes to execute at a lower priority than general user processes. The /bin/nice(1) and npri(1M) commands allow the user to control the priority of their processes on the system. The nice command functions as follows:
nice [ - increment ] command
When you form your command line using /bin/nice, you fill in the increment field with a number between 1 and 19. If you do not fill in a number, a default of 10 is assumed. The higher the number you use for the increment, the lower your process' priority will be (19 is the lowest possible priority; all numbers greater than 19 are interpreted as 19). The csh(1) shell has its own internal nice functions, which operate differently from the nice command, and are documented in the csh(1) reference page.
After entering the nice command and the increment on your command line, give the command as you would ordinarily enter it. For example, if the user ``joe'' wants to make his costly compile command described in the ps -ef listing above happen at the lowest possible priority, he forms the command line as follows:
nice -19 cc -o prog prog.c
If a process is invoked using nice, the total amount of CPU time required to execute the program does not change, but the time is spread out, since the process executes less often.
The superuser (root) is the only user who can give nice a negative value and thereby increase the priority of a process. To give nice a negative value, use two minus signs before the increment. For example:
nice --19 cc -o prog prog.c
The above command endows that process with the highest priority a user process may possess. The superuser should not use this feature frequently, as even a single process that has been upgraded in priority causes a significant system slowdown for all other users. Note that /bin/csh has a built-in nice program that uses slightly different syntax than that described here. For complete information on csh, see the csh(1) reference page.
The npri command allows users to make their process' priority nondegrading. In the normal flow of operations, a process loses priority as it executes, so large jobs typically use fewer CPU cycles per minute as they grow older. (There is a minimum priority, too. This priority degradation simply serves to maintain performance for simple tasks.) By using npri, the user can set the nice value of a process, make that process non-degrading, and also set the default time slice that the CPU allocates to that process. npri also allows you to change the priority of a currently running process. The following example usage of npri sets all the possible variables for a command:
npri -h 10 -n 10 -t 3 cc -o prog prog.c
In this example, the -h flag sets the nondegrading priority of the process, while the -n flag sets the absolute nice priority. The -t flag sets the time slice allocated to the process. IRIX uses a 10-millisecond time slice as the default, so the example above sets the time slice to 30 milliseconds. For complete information about npri and its flags and options, see the npri(1) reference page.
The superuser can change the priority of a running process with the renice(1M) or npri commands. Only the superuser can use these commands. renice is used as follows:
renice increment pid [-u user] [-g pgrp]
In the most commonly used form, renice is invoked on a specific process that is using system time at an overwhelming rate. However, you can also invoke it with the -u flag to lower the priority of all processes associated with a certain user, or with the -g flag to lower the priorities of all processes associated with a process group. More options exist and are documented in the renice(1M) reference page.
The npri command can also be used to change the parameters of a running process. This example changes the parameters of a running process with npri:
npri -h 10 -n 10 -t 3 -p 11962
The superuser can use renice or npri to increase the priority of a process or user, but this can severely impact system performance.
From time to time a process may use so much memory, disk, or CPU time that your only alternative is to terminate it before it causes a system crash. Before you kill a process, make sure that the user who invoked the process will not try to invoke it again. You should, if at all possible, speak to the user before killing the process, and at a minimum you should notify the user that the process was prematurely terminated and give a reason for the termination. If you do this, the user can reinvoke the process at a lower priority or possibly use the system's job processing facilities (at, batch, and cron) to execute the process at another time.
To terminate a process, you use the kill command. Typically, for most terminations, you should use the kill -15 variation. The -15 flag indicates that the process is to be allowed time to exit gracefully, closing any open files and descriptors. The -9 flag to kill terminates the process immediately, with no provision for cleanup. If the process you are going to kill has any child processes executing, using the kill -9 command may cause those child processes to continue to exist on the process table, though they will not be responsive to input. The wait(1) command, given with the process number of the child process, removes them. For complete information about the syntax and usage of the kill command, see the kill(1) reference page. You must always know the PID of the process you intend to kill with the kill command.
The killall(1M) command allows you to kill processes by their command name. For example, if you wish to kill the program a.out that you invoked, use the syntax:
killall a.out
This command allows you to kill processes without the time-consuming task of looking up the process ID number with the ps(1M) command.
Note: This command kills all instances of the named program running under your shell and if invoked with no arguments, kills all processes on the system that are killable by the user who invoked the command. For ordinary users, these are simply the processes invoked and forked by that user, but if invoked by root, all processes on the system will be killed. For this reason, this command should be used carefully.
Use the date(1) command to set the date and time. For example, to set the date to April 1st, 1999, and the time to 09:00, log in as root and enter:
date 0401090099
Changing the date and time on a running system can have unexpected consequences. Users and administrators use system scheduling utilities (at(1), cron(1), and batch(1)) to perform commands at specified times. If you change the effective date or time on the system, these commands may not execute at the desired times. Similarly, if your users use the make(1) utility provided with the system, the commands specified in Makefiles can incorrectly compile or process your users' work. Always try to keep your system date and time accurate within reason. Random changes of the date and time can be extremely inconvenient and possibly destructive to users' work.
If timed(1M) is running on the system, and it is a slave system, the time is reset by timed and not the above command. For more information, see the timed(1M) reference page.
The file /etc/motd contains the ``message of the day.'' This message is displayed on a user's screen, either by /etc/profile if the user runs Bourne shell, or by /etc/cshrc if the user runs C shell, when the user first logs in to the system.
You can place announcements of system activity in the motd file. For example, you should warn users of scheduled maintenance, changes in billing rates, new hardware and software, and any changes in the system or site configuration that affect them.
Since users see this message every time they log in, you should change it frequently to keep it from becoming stale. If users see the same message repeatedly, they lose interest in reading the message of the day and can miss an important announcement.
Make sure you remove outdated announcements. If nothing new is happening on the system, trim the file to a short ``welcome to the system'' message.
A typical motd file looks something like this:
Upcoming Events: --------------- 26 November -- The system will be down from 8PM until Midnight for a software upgrade. We are installing FareSaver+, Release 3.2.2d. Watch this space for further details. 28 November through 31 November -- We will be operating with a minimal staff during the holiday. Please be patient if you need computer services. Use the admin beeper (555-3465) if there is a serious problem.
The motd file is used more frequently on servers than on workstations, but can be handy for networked workstations with guest accounts. You can also send electronic mail to all people who use the system, but this method consumes more disk space, and users may accidentally skip over the mail in their mailboxes.
The file /etc/issue is displayed before the login prompt is given to someone attempting to log in to a system over a serial line or the network. If /etc/issue does not exist, or is empty, no message is displayed. This is essentially different from /etc/motd because it is displayed before the login prompt. This message is often used to notify potential users of rules about using the equipment; for example, a disclaimer that the workstation or server is reserved for employees of a particular corporation and that intruders will be prosecuted for unauthorized use.
The File Alteration Monitor (famd) is a daemon that monitors files and directories. Application writers can include certain function calls in their applications to let famd know that they want to be informed of changes to whichever files and/or directories they specify. WorkSpace and Mailbox are two applications that use famd; WorkSpace uses it to keep the directory views up to date, and Mailbox uses it to know when to indicate the arrival of new mail.
The famd daemon runs only when applications using it are running; it exits after all programs using it have stopped.
Sometimes, when attempting to start up an application which uses famd, an error message is displayed:
Cannot connect with File Alteration Monitor (fam)
There are several reasons why this message appears. Below are some of the common ways to troubleshoot the problem.
If you have the optional NIS (YP) software installed at your site, and you are using another manufacturer's system as your NIS master, with no rpc entries for sgi_toolkitbus and sgi_fam, this section provides the information to correct the error message.
Depending on the operating system (the Sun 3.x or the Sun 4.0) on the Sun NIS (YP) server, one of the two following solutions applies.
Sun 3.x
If the Sun Workstation is running version 3.x of Sun/OS, then two entries need to be added to the /etc/rpc database on the Sun NIS server machine. They are sgi_toolkitbus391001 and sgi_fam391002
On the NIS server, enter the command:
cd /usr/etc/yp make rpc
It may take as much as an hour before the NIS server pushes this information
to its clients.
Sun 4.0
If the Sun Workstation is running version 4.0 of Sun/OS or later, then two entries need to be added to the /etc/rpc database on the Sun NIS server machine. They are sgi_toolkitbus391001 and sgi_fam391002.
On the NIS server, type:
cd /var/yp make rpc
It may take as much as an hour before the NIS server pushes this information to its clients.
Note: If the NIS server machine is neither an SGI or Sun, the same rpc entries must be added, but the syntax may be different.
From a shell window, enter the command:
ls -l /usr/etc/fam
If the file is not found, you must reinstall the software package:
eoe2.sw.envm.
The famd daemon is enabled via the /usr/etc/inetd.conf file, which is read when the system starts up the network. Even if the system is not connected via the network to other systems, the network software must be started.
If the message:
portmapper failure
is displayed, it is also a sign that the network is not active.
If the command:
/etc/chkconfig | grep network
returns the message:
network off
Turn the network on by entering the command (as root):
/etc/chkconfig network on
and then either reboot your system by entering the command:
reboot
or just start up the network by issuing the command:
/etc/init.d/network start
Applications connect to famd via the localhost. Therefore, there must be a localhost entry in the /etc/hosts file.
This entry is in the hosts file by default, but sometimes gets removed. The correct entry would be:
127.0.0.1 localhost
Make sure that both sgi_famd and sgi_toolkitbus are running by entering the command:
/usr/etc/rpcinfo -p
In addition to other daemons running, you should see the following entries:
391002 1 tcp 1086 sgi_fam 391001 1 tcp 1087 sgi_toolkitbus
If you do not see these lines, check your /usr/etc/inetd.conf file. The following entries must be in that file:
sgi_fam/1 stream rpc/tcp wait root /usr/etc/fam famd sgi_toolkitbus/1 stream rpc/tcp wait root /usr/etc/rpc.toolkitbus toolkitbusd
If those lines are not in the file, you must add them, and then restart your network by entering the following command, as root:
/etc/init.d/network stop /etc/init.d/network start
The permissions on the /usr/lib/vadmin file should be:
drwxr-xr-x 2 root sys
If none of the listed problems exists, reinstall eoe2.sw.fonts. This will install a file called /usr/sysgen/boot/imon.o. Confirm that the file is there, and then use the autoconfig-vf command to build a new kernel. Then reboot your system to install the new kernel.
This section describes general operating policies for you, the site administrator. For a discussion of site policies, especially as they affect your users, see "System and Site Policies" in this guide.
Many administrative tasks require the system to be shut down to a run level other than the multiuser state. This means that conventional users cannot access the system. Just before the system is taken out of the multiuser state, users on the system are requested to log off. You should do these types of tasks when they will interfere the least with the activities of the user community.
Sometimes situations arise that require the system to be taken down with little or no notice provided to the users. This is often unavoidable, but try to give at least five to fifteen minutes of notice, if possible.
In general, try to provide the user community as much notice as possible about events affecting the use of the system. When the system must be taken out of service, also tell the users when to expect the system to be available. Use the ``message of the day'' file /etc/motd to keep users informed about changes in hardware, software, policies, and procedures.
At your discretion, the following actions should be prerequisites for any task that requires the system to leave the multiuser state:
When possible, perform service-affecting tasks during periods of low
system use. For scheduled actions, use /etc/motd to inform users
of future actions.
Check to see who is logged in before taking any actions that would affect
a logged-in user. You can use the /etc/whodo, /bin/who and
/usr/bsd/w commands to see who is on the system. You may also wish
to check for large background tasks, such as background compilations, by
executing ps -ef.
If the system is in use, provide the users advanced warning about changes in system states or pending maintenance actions. For immediate actions, use the /etc/wall command to send a broadcast message announcing that the system will be taken down at a given time. Give the users a reasonable amount of time (five to fifteen minutes) to terminate their activities and log off before taking the system down.
It is important to keep a complete set of records about each system you administer. A system log book is a useful tool when troubleshooting transient problems or when trying to establish system operating characteristics over a period of time. Keeping a hardcopy book is important, since you won't be able to refer to an online log if you have trouble starting the system.
Some of the things that you should consider entering into the log book are:
maintenance records (dates and actions)
printouts of error messages and diagnostic phases
equipment and system configuration changes (dates and actions), including
serial numbers of various parts (if applicable)
copies of important configuration files
the output of prtvtoc(1M) for each disk on the system
the /etc/passwd file
the /etc/group file
the /etc/fstab file
the /etc/exports file
The format of the system log and the types of items noted in the log should follow a logical structure. Think of the log as a diary that you update periodically. To a large measure, how you use your system will dictate the form and importance of maintaining a system log.
This section briefly describes the directories and files that a system administrator uses frequently. For additional information on the formats of the system files, refer to the IRIX reference pages.
Appendix B, "IRIX Device Files,"contains further information on the device files and directories that reside in the /dev directory.
The main directories of the root file system (/) are as follows:
The following directories are important in the administration of your system:
The following files are important in the administration of your system:
The IRIX system can run in either single-user or multiuser mode. In single-user mode, only a few processes are active on the system, no graphics are available, and only a single login is allowed. In multiuser mode, there can be multiple login sessions, many files open at once, and many active processes, including numerous background daemons.
The init program controls whether the system is in the multiuser or single-user state. Each possible state that the system can be in is assigned a label, either a number or a letter. The shutdown state is state 0. Single-user mode is state s.
Multiuse state labeling is more complex, because there can be great variations in multiuser states. For example, in one multiuser state, there can be unlimited logins, but in another state there can be a restricted number of logins. The different states can all be assigned different numbers.
The state of the system is controlled by the file /etc/inittab. This file lists the possible states, and the label associated with each.
When you bring the system to standard multiuser mode, init state 2, the following happen:
The file systems are mounted.
The cron daemon is started for scheduled tasks.
Network services are started, if turned on.
The serial-line networking functions of uucp are available for
use.
The spooling and scheduling functions of the lp package (if added
to the system) are available for use.
Users can log in.
Not all activities can or should be performed in the multiuser state. Some tasks, such as installing software that requires the miniroot and checking file systems must be done with the system in single-user mode.
There are many synonyms for the system state. These include:
init state
run state
run level
run mode
system state
Likewise, each system state may be referred to in a number of ways; for example:
single user
single-user mode
run level 1
Table 2-4 shows the various possible states of the operating system as it is shipped. You can, of course, create your own custom states.
| Run Level | Description |
|---|---|
| 0 | Power-down state. |
| 1, s, or S | Single-user mode is used to install/remove software utilities, run file system backups/restores, and check file systems. This state unmounts everything except root, and kills all user processes except those that relate to the console. |
| 2 | Multiuser mode is the normal operating mode for the system. The default is that the root (/) and user (/usr) file systems are mounted in this mode. When the system is powered up, it is put in multiuser mode. |
| 6 | Reboot mode is used to bring down the system and then bring it back up again. This mode is useful when you are changing certain system configuration parameters. |
The init process is the first general process created by the system at startup. It reads the file /etc/inittab, which defines exactly which processes exist for each run level.
In the multiuser state (run level 2), init scans the file for entries that have a tag (also 2) for the run level and executes everything after the third colon on the line containing the tag. For complete information, see the inittab(4) reference page.
The system /etc/inittab looks something like this:
is:2:initdefault: fs::sysinit:/etc/bcheckrc </dev/console >/dev/console 2>&1 mt::sysinit:/etc/brc </dev/console >/dev/console 2>&1 s0:06s:wait:/etc/rc0 >/dev/console 2>&1 </dev/console s1:1:wait:/etc/shutdown -y -iS -g0 >/dev/console 2>&1 </dev/console s2:23:wait:/etc/rc2 >/dev/console 2>&1 </dev/console s3:3:wait:/etc/rc3 >/dev/console 2>&1 </dev/console or:06:wait:/etc/umount -ak -b /proc,/debug > /dev/console 2>&1 of:0:wait:/etc/uadmin 2 0 >/dev/console 2>&1 </dev/console RB:6:wait:echo "The system is being restarted." >/dev/console rb:6:wait:/etc/uadmin 2 1 >/dev/console 2>&1 </dev/console #
This display has been edited for brevity; the actual /etc/inittab file is lengthy. If /etc/inittab is removed by mistake and is missing during shutdown, init enters the single-user state (init s). While entering single-user state, /usr remains mounted, and processes not spawned by init continue to run. Immediately replace /etc/inittab before changing states again. The format of each line in inittab is:
id:level:action:process
where:
id is one or two characters that uniquely identify an entry.
level is zero or more numbers and letters (0 through 6, s, a, b, and
c) that determine in what level(s) action is to take place. If level is
null, the action is valid in all levels.
action can be one of the following:
sysinit
Run process before init sends anything to the system console (Console
Login).
bootwait
Start process the first time init goes from single-user to multiuser
state after the system is started. (If initdefault is set to 2, the process
runs right after the startup.) init starts the process, waits for its termination
and, when it dies, does not restart the process.
wait
When going to level, start process and wait until it has finished.
initdefault
When init starts, it enters level; the process field for this action
has no meaning.
once
Run process once. If it finishes, don't start it again.
powerfail
Run process whenever a direct powerdown of the computer is requested.
respawn
If process does not exist, start it, wait for it to finish, and
then start another.
ondemand
Synonymous with respawn, but used only with level a, b, or c.
off
When in level, kill process or ignore it.
process is any executable program, including shell procedures.
# can be used to add a comment to the end of a line. init ignores all lines beginning with the # character.
When changing levels, init kills all processes not specified for that level.
When your system is up and running, it is usually in multiuser mode. It is only in this mode that the full power of IRIX is available to your users.
When you power up your system, it enters multiuser mode by default. (You can change the default by modifying the initdefault line in your inittab file.) In effect, going to the multiuser state follows these stages (see Table 2-4, "System States,"):
The operating system loads and the early system initializations are
started by init.
The run level change is prepared by the /etc/rc2 procedure.
The system is made public through the spawning of getty processes along the enabled terminal lines.
Just after the operating system is first loaded into physical memory through the specialized boot programs that are resident in the PROM hardware, the init process is created. It immediately scans /etc/inittab for entries of the type sysinit:
fs::sysinit:/etc/bcheckrc </dev/console >/dev/console 2>&1 mt::sysinit:/etc/brc </dev/console >/dev/console 2>&1
These entries are executed in sequence and perform the necessary early initializations of the system. Note that each entry indicates a standard input/output relationship with /dev/console. This establishes communication with the system console before the system is brought to the multiuser state.
Now the system is placed in a particular run level. First, init scans the table to find an entry that specifies an action of the type initdefault. If it finds one, it uses the run level of that entry as the tag to select the next entries to be executed. In our sample /etc/inittab, the initdefault entry is run level 2 (the multiuser state):
is:2:initdefault: s2:23:wait:/etc/rc2 >/dev/console 2>&1 </dev/console co:23:respawn:/etc/gl/conslog t1:23:respawn:/etc/getty -s console ttyd1 co_9600 #altconsole t2:23:off:/etc/getty ttyd2 co_9600 # port 2 t3:23:off:/etc/getty ttyd3 co_9600 # port 3 t4:23:off:/etc/getty ttyd4 co_9600 # port 4
The other entries shown above specify the actions necessary to prepare the system to change to the multiuser run level. First, /etc/rc2 is executed. It executes all files in /etc/rc2.d that begin with the letter S, accomplishing (among other things) the following:
Sets up and mounts the file systems
Starts the cron daemon
Makes uucp available for use
Makes the line printer (lp) system available for use, if installed
Starts accounting, if installed and configured on
Starts networking, if installed and configured on
Starts sar, if installed and configured on
Starts the mail daemon
Starts the system monitor
init then starts a getty for the console and starts getty on the lines connected to the ports indicated.
At this point, the full multiuser environment is established, and your system is available for users to log in.
To change run levels, the system administrator enters a command that directs init to execute entries in /etc/inittab for a new run level, such as multi, single, or reboot. Then key procedures, such as shutdown, /etc/rc0, and /etc/rc2, are run to initialize the new state.
The new state is reached. If it is state 1 (single-user mode), the system administrator can continue.
Run levels 0, 2, and 3 each have a directory of files that are executed in transitions to and from that level. These directories are rc0.d, rc2.d, and rc3.d, respectively. All files in these directories are linked to files in /etc/init.d. The run-level file names look like this:
S00name
or
K00name
The filenames can be split into three parts:
For example, the init.d file cron is linked to the rc2.d file and rc0.d file S75cron. When you enter init 2, this file is executed with the start option: sh S75cron start. When you enter init 0, this file is executed with the stop option: sh K70cron stop. This particular shell script executes /sbin/cron when run with the start option and kills the cron process when run with the stop option.
Because these files are shell scripts, you can read them to see what they do. You can modify these files, though it is preferable to add your own since the delivered scripts may change in future releases. To create your own scripts, follow these rules:
Place the file in /etc/init.d.
Symbolically link the file to files in appropriate run state directories,
using the naming convention described above.
Have the file accept the start and/or stop options.
Note that it may prove easier to simply copy an existing script from the directory and make appropriate changes.
Sometimes you must perform administrative functions, such as backing up the root file system, in single-user mode.
Use the shutdown command. This procedure executes all the files in /etc/rc0.d by calling the /etc/rc0 procedure. The shutdown command does the following things, among others:
Closes all open files and stops all user processes
Stops all daemons and services
Writes all system buffers out to the disk
Unmounts all file systems except root
The entries for single-user processing in the sample /etc/inittab are:
s1:1:wait:/etc/shutdown -y -iS -g0 >/dev/console 2>&1 </dev/console
There are three recommended ways to start the shutdown to single-user mode:
You can enter the shutdown -i1 command (recommended). The option
-g specifies a grace period between the first warning message and
the final message.
You can enter the single command, which runs a shell script that
switches to single-user mode and turns the getty processes off.
You can enter the init 1 command, which forces the init process to scan the table. The first entry it finds is the s1 entry, and init starts the shutdown processing according to that entry.
Now the system is in the single-user environment, and you can perform the appropriate administrative tasks.
The following entries in /etc/inittab power off the system:
s0:06s:wait:/etc/rc0 >/dev/console 2>&1 </dev/console of:0:wait:/etc/uadmin 2 0 >/dev/console 2>&1 </dev/console
Always attempt to shut the system down gracefully. You can either enter the powerdown command, the init 0 command, or directly invoke the /etc/shutdown -i0 command.
In either case, the /etc/shutdown and /etc/rc0 procedures are called to clean up and stop all user processes, daemons, and other services and to unmount the file systems. Finally, the /sbin/uadmin command is called, which indicates that the last step (physically removing power from the system) is under firmware control.
In the course of maintaining your system, you are likely to receive files in various versions of the PostScript format. Following are some of the main differences between the Encapsulated PostScript® File (EPSF) version 3.0 format and PostScript file format:
EPSF is used to describe the appearance of a single page, while the
PostScript format is used to describe the appearance of one or more pages.
EPSF requires the following two DSC (document structuring conventions) Header comments:
%!PS-Adobe-3.0 EPSF-3.0 %%BoundingBox: llx lly urx ury
If a PS 3.0 file conforms to the document structuring conventions, it should start with the comment:
%!PS-Adobe-3.0
A PS file does not have to contain any DSC comment statements if it
does not conform to the DS conventions.
Some PostScript language operators, such as copypage, erasepage, or exitserver must not be used in an EPS file.
Certain rules must be followed when some other PostScript operators, such as nulldevice, setscreen, or undefinefont are used in an EPS file.
All PostScript operators can be used in a PS file.
An EPS file can be (and usually is) inserted into a PS file, but a PS
file must not be inserted into an EPS file if that will violate the rules
for creating valid EPS files.
An EPS file may contain a device-specific screen preview for the image
it describes. A PS file usually contains screen previews only when EPS
files are included in that PS file.
The recommended file name extension for EPS files is . EPS or . eps, while the recommended file name extension for PS files is . PS or . ps.
The EPSF format was designed for importing the PostScript description of a single page or part of a page, such as a figure, into a document, without affecting the rest of the description of that document. EPS code should be encapsulated, i.e., it should not interfere with the PS code that may surround it, and it should not depend on that code.
The EPSF format is usually used for the output from a program that was designed for the preparation of illustrations or figures, (such as the Adobe Illustrator) and as input into desktop publishing programs (such as the Frame Technology's FrameMaker). Most desktop publishing programs can produce the description of a document in the PostScript format that may include the imported EPS code.
For more information about these formats, see the book PostScript Language Reference Manual, Second Edition, Addison-Wesley Publishing Company, Inc., Reading, MA, 1990. You can get several documents on the EPS and PS formats from the Adobe Systems PostScript file server by entering the following at a UNIX prompt, and then following the instructions you get from the file server:
mailps-file-server@adobe.com
Subject:help
Ctrl-D
You can get a description of the EPSF format in the PS format by sending the following message to that file server:
sendDocumentsEPSF2.0.ps
Send feedback to Technical Publications.
Copyright © 1997, Silicon Graphics, Inc. All Rights Reserved. Trademark Information