


4.5. Глобальные вычислительные операции над распределенными данными
В параллельном программировании математические операции над блоками данных, распределенных по процессорам, называют глобальными операциями редукции. В общем случае операцией редукции называется операция, аргументом которой является вектор, а результатом - скалярная величина, полученная применением некоторой математической операции ко всем компонентам вектора. В частности, если компоненты вектора расположены в адресных пространствах процессов, выполняющихся на различных процессорах, то в этом случае говорят о глобальной (параллельной) редукции. Например, пусть в адресном пространстве всех процессов некоторой группы процессов имеются копии переменной var (необязательно имеющие одно и то же значение), тогда применение к ней операции вычисления глобальной суммы или, другими словами, операции редукции SUM возвратит одно значение, которое будет содержать сумму всех локальных значений этой переменной. Использование этих операций является одним из основных средств организации распределенных вычислений.
В MPI глобальные операции редукции представлены в нескольких вариантах:
Функция MPI_Reduce выполняется следующим образом. Операция глобальной редукции, указанная параметром op, выполняется над первыми элементами входного буфера, и результат посылается в первый элемент буфера приема процесса root. Затем то же самое делается для вторых элементов буфера и т.д.
| IN | sendbuf | - | адрес начала входного буфера; |
| OUT | recvbuf | - | адрес начала буфера результатов (используется только в процессе-получателе root); |
| IN | count | - | число элементов во входном буфере; |
| IN | datatype | - | тип элементов во входном буфере; |
| IN | op | - | операция, по которой выполняется редукция; |
| IN | root | - | номер процесса-получателя результата операции; |
| IN | comm | - | коммуникатор. |
На рис. 4.8 представлена графическая интерпретация операции Reduce. На данной схеме операция "+" означает любую допустимую операцию редукции.
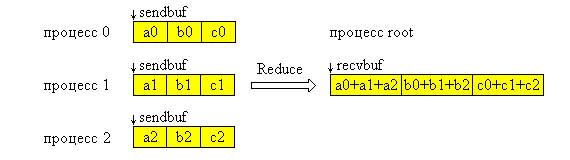
Рис. 4.8. Графическая интерпретация операции Reduce.
В качестве операции op можно использовать либо одну из предопределенных операций, либо операцию, сконструированную пользователем. Все предопределенные операции являются ассоциативными и коммутативными. Сконструированная пользователем операция, по крайней мере, должна быть ассоциативной. Порядок редукции определяется номерами процессов в группе. Тип datatype элементов должен быть совместим с операцией op. В таблице 4.1 представлен перечень предопределенных операций, которые могут быть использованы в функциях редукции MPI.
| Название | Операция | Разрешенные типы |
| MPI_MAX MPI_MIN |
Максимум Минимум |
C integer, FORTRAN integer, Floating point |
| MPI_SUM MPI_PROD |
Сумма Произведение |
C integer, FORTRAN integer, Floating point, Complex |
| MPI_LAND MPI_LOR MPI_LXOR |
Логическое AND Логическое OR Логическое исключающее OR |
C integer, Logical |
| MPI_BAND MPI_BOR MPI_BXOR |
Поразрядное AND Поразрядное OR Поразрядное исключающее OR |
C integer, FORTRAN integer, Byte |
| MPI_MAXLOC MPI_MINLOC |
Максимальное значение и его индекс Минимальное значение и его индекс |
Специальные типы для этих функций |
В таблице используются следующие обозначения:
| C integer: | MPI_INT, MPI_LONG, MPI_SHORT, MPI_UNSIGNED_SHORT, MPI_UNSIGNED, MPI_UNSIGNED_LONG |
| FORTRAN integer: | MPI_INTEGER |
| Floating point: | MPI_FLOAT, MPI_DOUBLE, MPI_REAL, MPI_DOUBLE_PRECISION, MPI_LONG_DOUBLE |
| Logical: | MPI_LOGICAL |
| Complex: | MPI_COMPLEX |
| Byte: | MPI_BYTE |
Операции MAXLOC и MINLOC выполняются над специальными парными типами, каждый элемент которых хранит две величины: значения, по которым ищется максимум или минимум, и индекс элемента. В MPI имеется 9 таких предопределенных типов.
| C: | ||||
|---|---|---|---|---|
| MPI_FLOAT_INT | float | and | int | |
| MPI_DOUBLE_INT | double | and | int | |
| MPI_LONG_INT | long | and | int | |
| MPI_2INT | int | and | int | |
| MPI_SHORT_INT | short | and | int | |
| MPI_LONG_DOUBLE_INT | long double | and | int | |
| FORTRAN: | ||
|---|---|---|
| MPI_2REAL | REAL and REAL | |
| MPI_2DOUBLE_PRECISION | DOUBLE PRECISION and DOUBLE PRECISION | |
| MPI_2INTEGER | INTEGER and INTEGER | |
Функция MPI_Allreduce сохраняет результат редукции в адресном пространстве всех процессов, поэтому в списке параметров функции отсутствует идентификатор корневого процесса root. В остальном, набор параметров такой же, как и в предыдущей функции.
| IN | sendbuf | - | адрес начала входного буфера; |
| OUT | recvbuf | - | адрес начала буфера приема; |
| IN | count | - | число элементов во входном буфере; |
| IN | datatype | - | тип элементов во входном буфере; |
| IN | op | - | операция, по которой выполняется редукция; |
| IN | comm | - | коммуникатор. |
На рис. 4.9 представлена графическая интерпретация операции Allreduce.
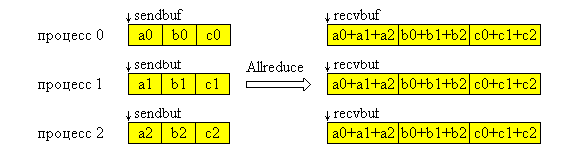
Рис. 4.9. Графическая интерпретация операции Allreduce.
Функция MPI_Reduce_scatter совмещает в себе операции редукции и распределения результата по процессам.
| IN | sendbuf | - | адрес начала входного буфера; |
| OUT | recvbuf | - | адрес начала буфера приема; |
| IN | revcount | - | массив, в котором задаются размеры блоков, посылаемых процессам; |
| IN | datatype | - | тип элементов во входном буфере; |
| IN | op | - | операция, по которой выполняется редукция; |
| IN | comm | - | коммуникатор. |
Функция MPI_Reduce_scatter отличается от MPI_Allreduce тем, что результат операции разрезается на непересекающиеся части по числу процессов в группе, i-ая часть посылается i-ому процессу в его буфер приема. Длины этих частей задает третий параметр, являющийся массивом. На рис. 4.10 представлена графическая интерпретация операции Reduce_scatter.
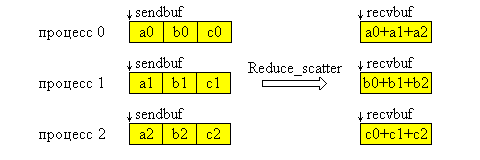
Рис. 4.10. Графическая интерпретация операции Reduce_scatter.
Функция MPI_Scan выполняет префиксную редукцию. Параметры такие же, как в MPI_Allreduce, но получаемые каждым процессом результаты отличаются друг от друга. Операция пересылает в буфер приема i-го процесса редукцию значений из входных буферов процессов с номерами 0, ... i включительно.
| IN | sendbuf | - | адрес начала входного буфера |
| OUT | recvbuf | - | адрес начала буфера приема |
| IN | count | - | число элементов во входном буфере |
| IN | datatype | - | тип элементов во входном буфере |
| IN | op | - | операция, по которой выполняется редукция |
| IN | comm | - | коммуникатор |
На Рис. 4.11 представлена графическая интерпретация операции Scan.
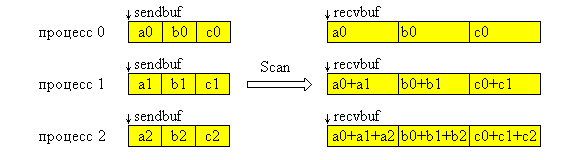
Рис. 4.11. Графическая интерпретация операции Scan.