


4.3. Функции распределения блоков данных по всем процессам группы
Семейство функций распределения блоков данных по всем процессам группы состоит из двух подпрограмм: MPI_Scatter и MPI_Scaterv.
Функция MPI_Scatter разбивает сообщение из буфера посылки процесса root на равные части размером sendcount и посылает i-ю часть в буфер приема процесса с номером i (в том числе и самому себе). Процесс root использует оба буфера (посылки и приема), поэтому в вызываемой им подпрограмме все параметры являются существенными. Остальные процессы группы с коммуникатором comm являются только получателями, поэтому для них параметры, специфицирующие буфер посылки, не существенны.
| IN | sendbuf | - | адрес начала размещения блоков распределяемых данных (используется только в процессе-отправителе root); |
| IN | sendcount | - | число элементов, посылаемых каждому процессу; |
| IN | sendtype | - | тип посылаемых элементов; |
| OUT | recvbuf | - | адрес начала буфера приема; |
| IN | recvcount | - | число получаемых элементов; |
| IN | recvtype | - | тип получаемых элементов; |
| IN | root | - | номер процесса-отправителя; |
| IN | comm | - | коммуникатор. |
Тип посылаемых элементов sendtype должен совпадать с типом recvtype получаемых элементов, а число посылаемых элементов sendcount должно равняться числу принимаемых recvcount. Следует обратить внимание, что значение sendcount в вызове из процесса root - это число посылаемых каждому процессу элементов, а не общее их количество. Операция Scatter является обратной по отношению к Gather. На рис. 4.5 представлена графическая интерпретация операции Scatter.
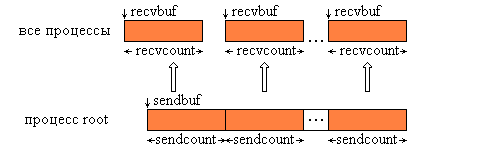
Рис. 4.5. Графическая интерпретация операции Scatter.
Пример использования функции MPI_Scatter
MPI_Comm comm; int rbuf[100], gsize; int root, *array; . . . . . . MPI_Comm_size(comm, &gsize); array = (int *) malloc(gsize * 100 * sizeof(int)); . . . . . . MPI_Scatter(array, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
Функция MPI_Scaterv является векторным вариантом функции MPI_Scatter, позволяющим посылать каждому процессу различное количество элементов. Начало расположения элементов блока, посылаемого i-му процессу, задается в массиве смещений displs, а число посылаемых элементов - в массиве sendcounts. Эта функция является обратной по отношению к функции MPI_Gatherv.
| IN | sendbuf | - | адрес начала буфера посылки (используется только в процессе-отправителе root); |
| IN | sendcounts | - | целочисленный массив (размер равен числу процессов в группе), содержащий число элементов, посылаемых каждому процессу; |
| IN | displs | - | целочисленный массив (размер равен числу процессов в группе), i-ое значение определяет смещение относительно начала sendbuf для данных, посылаемых процессу i; |
| IN | sendtype | - | тип посылаемых элементов; |
| OUT | recvbuf | - | адрес начала буфера приема; |
| IN | recvcount | - | число получаемых элементов; |
| IN | recvtype | - | тип получаемых элементов; |
| IN | root | - | номер процесса-отправителя; |
| IN | comm | - | коммуникатор. |
На рис. 4.6 представлена графическая интерпретация операции Scatterv.
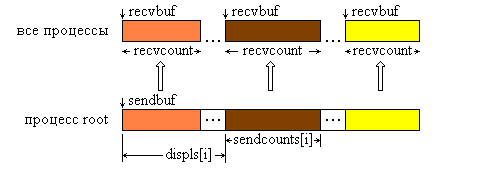
Рис. 4.6. Графическая интерпретация операции Scatterv.